Buzz
一款GitHub开源免费的,可以离线运行的语音识别软件。它有两个功能,一个是语音转文字,一个是实时语音识别。
特点
- 从麦克风实时转录和翻译成文本
- 导入音频和视频文件并导出文本到 TXT、SRT 和 VTT 字幕文件
- 支持Whisper、 Whisper.cpp、 与Whisper 兼容的 Hugging Face 模型和 OpenAI Whisper API
- 适用于 Mac、Windows 和 Linux
安装
以Windows系统为例简单说明,软件下载完成后,双击运行,进行安装:

根据个人情况选择是为所有用户安装,还是仅为当前用户安装

选择安装位置(老朋友都知道,小编习惯将软件安装在非系统盘,养成良好的软件安装习惯,从我做起)。

后面基本一路 Next 即可进入安装阶段,等待安装完成即可。
使用
运行 Buzz ,进入软件主界面

点击工具栏的 + 号,导入需要转文本的音频或视频文件,如下:

支持文件类型:
*.mp3,*.wav,*.m4a,*.ogg,*.mp4,*.webm,*.ogm,*.mov
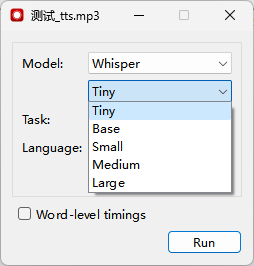
打开音频后,会进入设置窗口,Model选项为语音识别的模型,第一次使用时,会根据Model下方选择的不同的质量需求,下载指定的模型,具体如下:


Task任务只有两个选项,分别为Translate(翻译)、Transcribe(转录),可根据需要进行选择
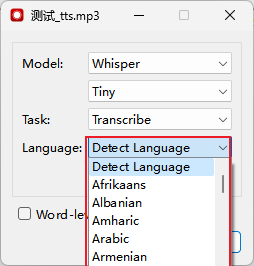
Language选项为语言设置选项,默认为detect language(自动检测语言),注意,这里的自动检测只是检测前几秒音频中的语言,稳妥起见,还是推荐自己指定语言。

设置完成,点击 Run

如上所述,第一次运行,本地没有任何模型,所以会自动开始下载模型文件,下载完成后会自动执行语音转文本任务。

状态栏显示 Completed (完成)后,使用鼠标双击这一行,就会弹出识别的字幕内容,如下:

可以看到,内容中有不少地方声音识别出来,但文字是不对的,还需要手动调整,不过小编只是为了演示,也以只选择了较小体量的Base模型,大家可以下载质量更高的模型进行尝试。

点击字幕列表右下角 Export (导出),可以选择导出为txt、srtvtt三种格式文件。
相关下载
https://www.123pan.com/s/IcP9-ZGOCA
本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习使用,请在下载后24小时内删除,严禁商用。若由于商用引起版权纠纷,一切责任均由使用者承担。
【注意:本站发布资源来源于网络搜集,均有较强时效性,请在下载前注意查看文章资源发布或更新时间,距离当前时间太久的资源不建议下载,特别是安卓专区相关资源,会有大概率失效无法使用】
评论(0)